My talk at GUADEC this year was titled Continuous Performance Testing on Actual Hardware, and covered a project that I’ve been spending some time on for the last 6 months or so. I tackled this project because of accumulated frustration that we weren’t making consistent progress on performance with GNOME. For one thing, the same problems seemed to recur. For another thing, we would get anecdotal reports of performance problems that were very hard to put a finger on. Was the problem specific to some particular piece of hardware? Was it a new problem? Was it an a problems that we have already addressed? I wrote some performance tests for gnome-shell a few years ago – but running them sporadically wasn’t that useful. Running a test once doesn’t tell you how fast something should be, just how fast it is at the moment. And if you run the tests again in 6 months, even if you remember what numbers you got last time, even if you still have the same development hardware, how can you possibly figure out what what change is responsible? There will have been thousands of changes to dozens of different software modules.
Continuous testing is the goal here – every time we make a change, to run the same tests on the same set of hardware, and then to make the results available with graphs so that everybody can see them. If something gets slower, we can then immediately figure out what commit is responsible.
We already have a continuous build server for GNOME, GNOME Continuous, which is hosted on build.gnome.org. GNOME Continuous is a creation of Colin Walters, and internally uses Colin’s ostree to store the results. ostree, for those not familiar with it is a bit like Git for trees of binary files, and in particular for operating systems. Because ostree can efficiently share common files and represent the difference between two trees, it is a great way to both store lots of build results and distribute them over the network.
I wanted to start with the GNOME Continuous build server – for one thing so I wouldn’t have to babysit a separate build server. There are many ways that the build can break, and we’ll never get away from having to keep a eye on them. Colin and, more recently, Vadim Rutkovsky were already doing that for GNOME Continuouous.
But actually putting performance tests into the set of tests that are run by build.gnome.org doesn’t work well. GNOME Continuous runs it’s tests on virtual machines, and a performance test on a virtual machine doesn’t give the numbers we want. For one thing, server hardware is different from desktop hardware – it generally has very limited graphics acceleration, it has completely different storage, and so forth. For a second thing, a virtual machine is not an isolated environment – other processes and unpredictable caching will affect the numbers we get – and any sort of noise makes it harder to see the signal we are looking for.
Instead, what I wanted was to have a system where we could run the performance tests on standard desktop hardware – not requiring any special management features.
Another architectural requirement was that the tests would keep on running, no matter what. If a test machine locked up because of a kernel problem, I wanted to be able to continue on, update the machine to the next operating system image, and try again.
The overall architecture is shown in the following diagram:
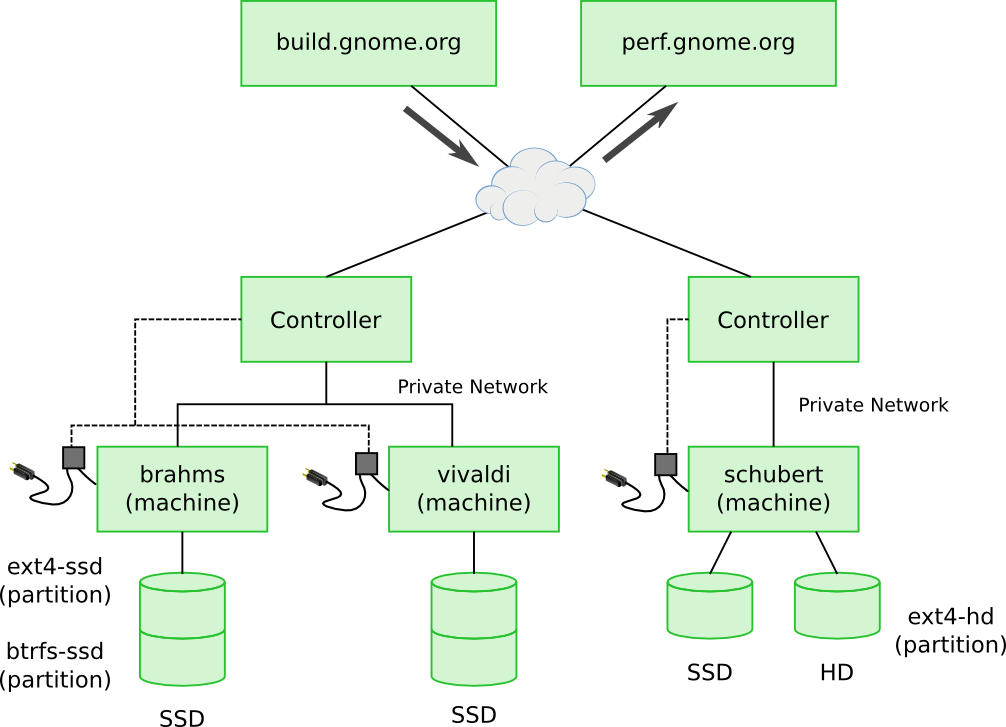 The most interesting thing to note in the diagram the test machines don’t directly connect to build.gnome.org to download builds or perf.gnome.org to upload the results. Instead, test machines are connected over a private network to a controller machine which supervises the process of updating to the next build and actually running, the tests. The controller has two forms of control over the process – first it controls the power to the test machines, so at any point it can power cycle a test machine and force it to reboot. Second, the test machines are set up to network boot from the test machines, so that after power cycling the controller machine can determine what to boot – a special image to do an update or the software being tested. The systemd journal from the test machine is exported over the network to the controller machine so that the controller machine can see when the update is done, and collect test results for publishing to perf.gnome.org.
The most interesting thing to note in the diagram the test machines don’t directly connect to build.gnome.org to download builds or perf.gnome.org to upload the results. Instead, test machines are connected over a private network to a controller machine which supervises the process of updating to the next build and actually running, the tests. The controller has two forms of control over the process – first it controls the power to the test machines, so at any point it can power cycle a test machine and force it to reboot. Second, the test machines are set up to network boot from the test machines, so that after power cycling the controller machine can determine what to boot – a special image to do an update or the software being tested. The systemd journal from the test machine is exported over the network to the controller machine so that the controller machine can see when the update is done, and collect test results for publishing to perf.gnome.org.
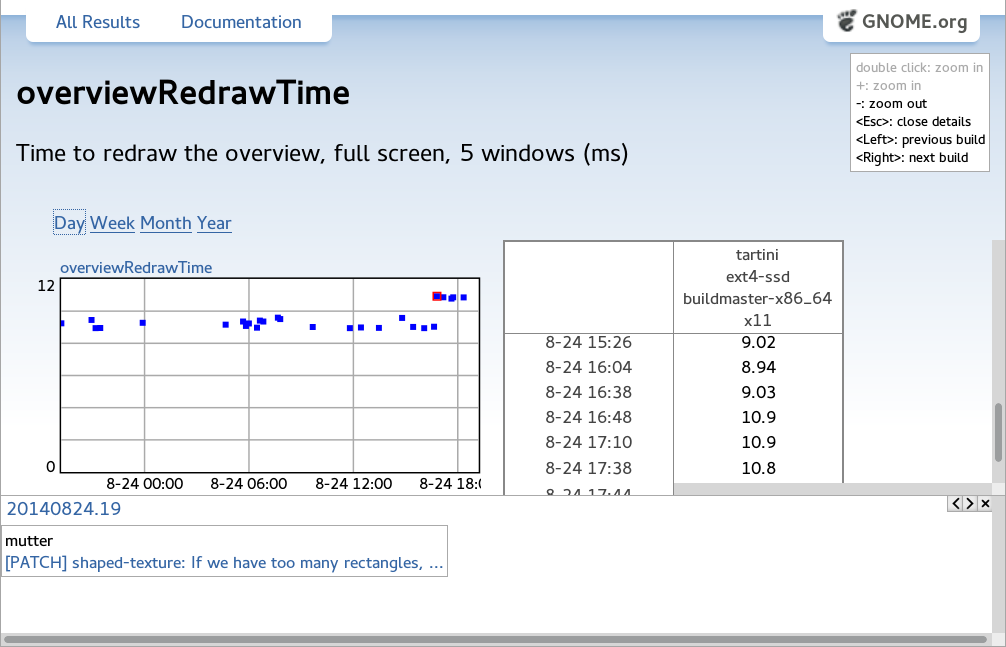
perf.gnome.org is live now, and tests have been running for the last three months. In that period, the tests have run thousands of times, and I haven’t had to intervene once to deal with a . Here’s perf.gnome.org catching a regression (fix)
 I’ll cover more about the details of how the hardware testing setup work and how performance tests are written in future posts – for now you can find some more information at https://wiki.gnome.org/Projects/HardwareTesting.
I’ll cover more about the details of how the hardware testing setup work and how performance tests are written in future posts – for now you can find some more information at https://wiki.gnome.org/Projects/HardwareTesting.
