A couple of weeks ago Dave Airlie pointed out to me that Alex Deucher had added RENDER extension acceleration for R3xx/R5xx to the Radeon EXA driver. Seeing an opportunity to have a desktop that was both composited and accelerated on my R300 laptop, I tried it out. The initial results: everything slowed to a crawl. I fixed one problem that was causing a software fallback for gradients, and the next bottleneck was text. Less than 18,000 glyphs / second. I eventually tracked down the R300-specific problem, and that got things to a usable rate: 130,000 glyphs / second. But still, that’s slower than unaccelerated text. How can we make it fast?
To make sure that everybody is on the same page about what we are trying to make fast, let me show a picture of a drawing some text via the RENDER extension:

It’s a two step process: first we take all the glyph images and draw them onto a mask. Then we draw the source color or pattern through that mask onto the destination surface. So, which of the two steps is slow? We can get a very good idea of that by measuring the drawing speed as a function of the size of glyph and of the number of glyphs in the string.
| R100 | R300 | i965 | i965-BB | |||||
|---|---|---|---|---|---|---|---|---|
| count | 10px | 24px | 10pt | 24px | 10px | 24px | 10px | 24px |
| 1 | 30300 | 30200 | 29400 | 29300 | 47500 | 47400 | 34500 | 34500 |
| 5 | 92900 | 90500 | 84500 | 81700 | 120000 | 119000 | 119000 | 119000 |
| 10 | 126000 | 111000 | 109000 | 108000 | 149000 | 148000 | 172000 | 172000 |
| 30 | 172000 | 127000 | 139000 | 138000 | 178000 | 178000 | 249000 | 238000 |
| 80 | 195000 | 130000 | 151000 | 151000 | 190000 | 190000 | 290000 | 278000 |
(Notes: All timings using EXA. R100/R300 timings on a P4-3.0Ghz, i965 timings on a core 2 dua 2.0Ghz. i965-BB is intel-batchbuffers branch, i965 master. Test program.)
We can also plot the numbers:
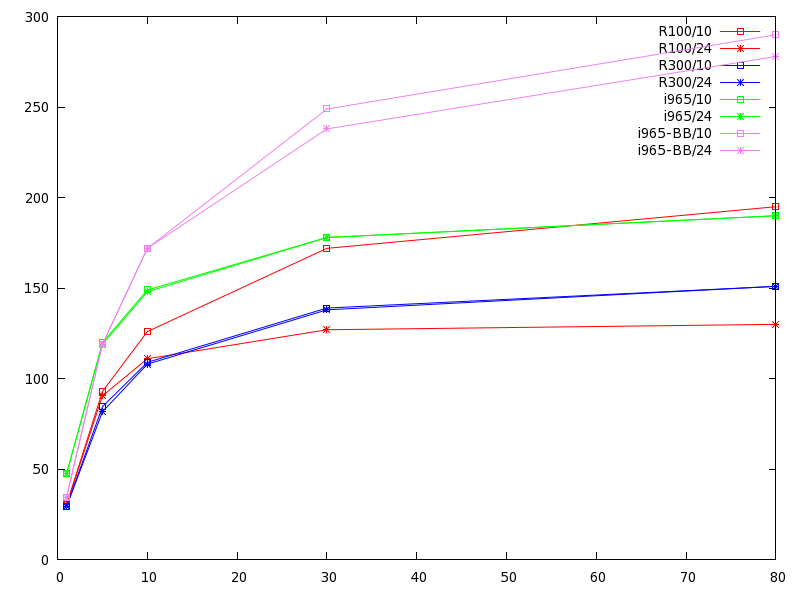
A couple of interesting things: first the amount of pixels we are pushing is completely irrelevant … on all the cards the 10 pixel and 24 pixel font sizes perform the same, even though there are almost 6 times as many pixels at the larger size (2.4^2 == 5.76.) Second, our performance in terms of glyphs/second is pretty much flat for all but the shortest strings. So we know what the bottleneck is: it’s the per-glyph setup cost of copying the glyphs onto the mask.
If we take a look at the EXA hooks for composite acceleration, we see the basic problem:
Bool (*PrepareComposite) (int op, PicturePtr pSrcPicture, PicturePtr pMaskPicture, PicturePtr pDstPicture, PixmapPtr pSrc, PixmapPtr pMask, PixmapPtr pDst); void (*Composite) (PixmapPtr pDst, int srcX, int srcY, int maskX, int maskY, int dstX, int dstY, int width, int height); void (*DoneComposite) (PixmapPtr pDst);
A composite operation consists of copying a number of rectangles from the same source, to the same destination, with the same operator. But in the building the mask, we are copying a number of rectangles from different sources. Each glyph must be added to the mask in a separate composite operation. And at the beginning and ends of a composite operation we do expensive stuff: at the beginning we set up all the state for the 3D engine. At the end we wait until the 3D engine is idle so we can go off and use the drawn result as a source for some other operation.
I had two thoughts initially: the first was to try and optimize separate composite operations done sequentially: if we do two operations in a row that need the 3D engine set up the same way, don’t set it up twice. The second was to extend the composite acceleration hooks so that we could change the source in the middle of an operation: to add a SwitchCompositeSource() that could be called between PrepareComposite() and DoneComposite(). But the first is tricky to get right if you want to avoid enough work to actually make a performance difference, and the second requires a minor version bump in EXA and is, beyond that, a hack. (Why just have an operation for switching the source, and not the operator or the mask.) Neither gets rid of the actual need to switch the source texture between every glyph: something that is inherently expensive to do for most graphics chipsets. (In the brave new world of the TTM memory manager, switching textures also means a lot of relocations for the submitted command buffer.)
Then Dave suggested something on IRC: what if instead of uploading each glyph into a separate glyph pixmap, we used a single glyph cache pixmap, uploaded glyphs there as needed, then composited to from that cache pixmap to the mask. That matches the current composite hooks perfectly, and allows us to set up the 3D engine once and just send a stream of vertices for each rectangle we want to draw to the card.
I took a stab at implementing the approach over the weekend and the results are definitely encouraging. Here’s the table and graph from above repeated with the new code:
| R100 | R300 | i965 | i965-BB | |||||
|---|---|---|---|---|---|---|---|---|
| count | 10pt | 24pt | 10pt | 24pt | 10pt | 24pt | 10pt | 24pt |
| 1 | 31600 | 31100 | 30100 | 29300 | 48700 | 47900 | 34500 | 43500 |
| 5 | 137000 | 110000 | 131000 | 127000 | 198000 | 195000 | 153000 | 152000 |
| 10 | 229000 | 131000 | 222000 | 221000 | 322000 | 319000 | 269000 | 269000 |
| 30 | 438000 | 156000 | 435000 | 431000 | 558000 | 541000 | 549000 | 496000 |
| 80 | 611000 | 159000 | 620000 | 504000 | 727000 | 600000 | 762000 | 593000 |
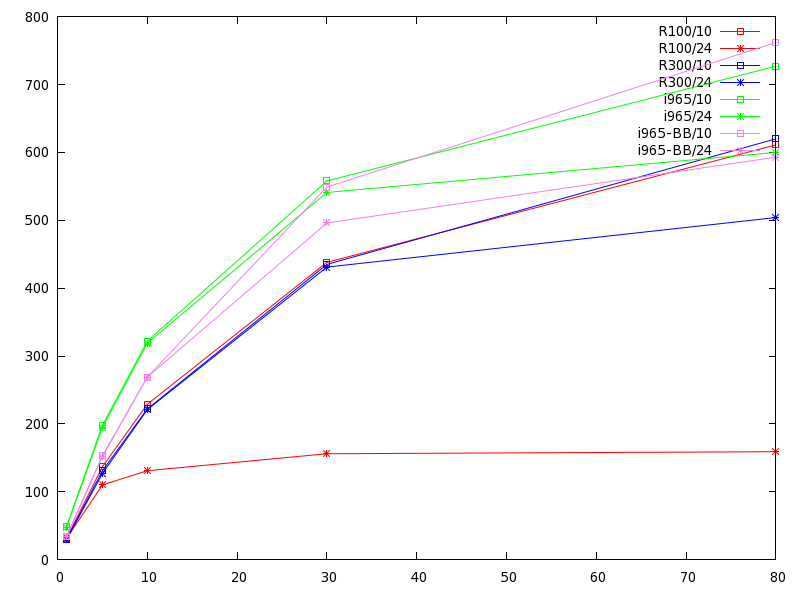
Obviously everything is much faster, but we also see a qualitative change: as compared to the previous numbers there is a much stronger dependence on the length of the glyph string (overall setup costs) and on the size of the glyphs (per-pixel costs.) We’ve taken the per-glyph setup cost mostly out of the equation. And at the larger glyph size the R100 starts falling way behind. It should be noted that there is significant overhead from my test code when we get to these speeds: ‘x11perf -aa10text’ is somewhat faster.
The code can be found in the glyph-cache branch of my xserver git tree at git://git.fishsoup.net/xserver. In an existing xserver git tree, you’d check out that branch as:
git remote add -f otaylor git://git.fishsoup.net/xserver git checkout -b glyph-cache otaylor/glyph-cache
What remains to be done? Well, first the current patch just uses static glyph cache size. The first time you draw an A8 glyph, you get a 300k pixmap allocated to hold 256 16×16 and 256 32×32 glyphs. The first time you draw a ARGB32 glyph (subpixel antialiasing) you get a 1.3M pixmap allocated. (4 times as big since each glyph is 4 times as big.) But 256 glyphs is not big enough for all languages. And immediately allocating 1.3M the first time we see an ARGB glyph is probably a bad idea, especially when memory is tight. A better approach would be to smart small, track the glyph cache hit rate, and at if we are getting a too low hit rate, dump the current cache, reallocate the cache to a larger size, and start over.
The second major thing left to do is to improve the way that glyphs are added to the cache pixmap. Right now, when a glyph is uploaded to the server by an application, it is immediately stored in a pixmap in video memory. With the glyph cache pixmap, it likely make more sense to keep the glyph in system memory until first needed, and then upload it directly to the glyph cache pixmap. I didn’t try to do that yet: what my patch does is simply copy directly from the in-memory glyph pixmap to the cache pixmap. So potential improvements from reducing the number of small pixmaps that must be memory managed are not yet achieved.

5 Comments
Nice work.
So, if I understand correctly, the acceleration profits all drivers, not only radeons ?
Hi! Good work. I’ve been using the latest git for a few days and now composite with EXA is finally usable, even with a old xserver (1.4.0.90).
To tell the truth, on my rv370 I’m getting higher results than you (300k char/s with metacity, 240k char/s with compiz), on #radeon agdf5 mentioned a libpciaccess bug, could it be that? (I had noticed the performance drop with recent xservers before)
Xav: I would expect it to be useful for pretty much any EXA-based driver that is accelerating RENDER. It certainly helps the Intel driver as well (the lines labeled i965.)
Giacomo: There are a lot of factors that can affect things, and it’s hard to sort them out without seeing a profile. I would certainly wonder if you are seeing software rendering. Offhand, I wouldn’t expect libpciaccess to be important here: with or without my patch the commands and data are going through the DRM. But I’m not an expert in that area.
I ‘m using intel driver and recently enabled EXA. The speed is *pathetic* compared to XAA, it’s like working on a 200MHz Pentium. All redraws are visible (you can see the screen filling…).
So thank you very much for this improvement, it is much needed!
This is very interesting and it will be a big improvement. I had an extension to the idea that might be useful and my ititial test seems to indicate that.
I am pasting in mail I sent to carl worth about the idea and my initial results.
…
I recently installed Ubuntu (Hardy Heron) on my rather ancient desktop at home. This machine is mostly used by my wife to read email and to view YouTube. The machine is rather memory limited 512 MB ram and an ATI Radeon 9550 with 64MB video RAM. As you can see not a great machine, but Linux was fine on it until I installed Hardy; now the machine feels as pigishly slow as a windows machine – ah well. To cut to the chase, I thought that things might improve if I enable hardware accelerated graphics and in particularly xgl+compiz. The good thing about the software is that it can be set up very little effort and the and the desktop effects seem to work quite well. But mow Firefox rendering is really slow and scrolling is glacial. That is not the worst of it, most video playback li more like a slugging slide-show. Before you ask I am using the proprietary fglx driver. Most of the time xgl shows over 30% CPU utilization, now I think this is because most websites have flash videos in advertisements, and xgl really has a lot of trouble that those. On the plus side the window manager is very smooth them moving windows around the screen even with the wobble effect and there is no visible repainting of the exposed area when moving windows. Although it is not significant that every Linux distribution I have used previously used would show a ‘trailing’ effect in particular going over the firefox browser.
The Premise
Any down to business, I was reading about the improvements you have been making to the hardware rendering portion of X and XAA rendering was still twice as fast as the EXA rendering that you are implementing. In a video presentation you mentioned that if the hardware was infinately fast that the max rate for glyph drawing would be about 700K/s and you are getting around 125K glyphs per sec. I am sure you have thought about this, if instead of displaying one glyph at a time we cached sequences of multiple glyphs at a time, would that not improve the performance of glyph display. Since regular text has a awful number repeated text fragments and if one considers how much zip compression can reduce a text file size, this seems to be an effective line of enquiry.
Some experiments
Purpose: See if is effective to cache common sequesnces of glyphs instead of individual glyphs. The idea is an extension of all the individual glyphs in a single image. For example:
How the sequences are generated:
the text “this is a test”
would generate the following doule and tripple sequences.
=> “th”, “thi”, “hi”, “his”, “is”, “is “, “s “, “s i”,
” i”, ” is”, “is”, “is “, “s “, “s a”, ” a”,
” a “, “a “, “a t”, ” t”, ” te”, “te”, “tes”, “es”, “est”, “st”
Clearly not all of these sequences are useful. So we need some heuristic to keep only the one that would be useful.
As stated earlier there is a rather efficient method of building these sequences using a ‘trie’ data structure. We start of by building 2 character sequences. Every time we see the same sequence again we increment the use count. When the use-count exceeds a pre-determined threshold say 10, we start to extend that pair to include a third characte. Further we cache an image of the two glyph sequence.
Again an example woul be useful. Suppose we have the sequence ‘th’ we see this occuring 10 time, we create an image for ‘th’ and we also extending the sequence for ‘th’
Now we might get:
Seequence Occurance
‘the’ 10
‘tho’ 3
‘thi’ 10
we would now create an image for ‘the’ but not for ‘tho’ and ‘thi’.
Assumptionns:
1> The glyph sequences to cache should be computed dynamically
2> The process should be efficient both in compution power and memory usage
3> The maximum sequence lengths should be determined in advance
4> The solution should be esay to implement.
5> English text was used for these experiments, use the text form of books in project Guttenburg
From my half remeberd data structure courses at school, I assumes that the trie data structure would probably be the most efficient way of determining the best glyph sequences. These are many methods of implementing the TRIE structure and I did find a a really good paper on efficient trie implemenation “An Efficient Implementation of Trie Structures (1992) , Jun-Ichi Aoe, Katsushi Morimoto, Takashi Sato; Software — Practice and Experience”, I did not use that code for these experiments. The purpose of the experiments was to determing if this would be a useful line to follow. I am please to report that the results are ensouraging:
I use a simple Trie implemenation i Java that is not particularly efficient and certainly I would not suggest that that this implememtation should be transcribed to C. I chose Java so as to do these experiments quickly. Secondly, I have not done graphics programming in over 10 years and I have no experience with OpenGL, so I did not attempt to do any graphics in these experiments.
Summary
As you can see I have presented the results for caching 2, 3, 4 glyph sequences. The results suggest we get very good inprovement with images generated for glyph pairs, and a 35% improvement if we use glyph triples (but we have to cache a far greater number of images) but the extra space may be worth the overhead. Above 3 we get much smaller improvement for a great deal of extra processing time and image caching, this in my opinion would not be worth the effort.
Results:
Run on Ubuntu 8.04
1 GHz Dell Pentium PIII 512 MB Ram
JRE java 6 – sun 1.6.0.06
Test
Up to 3 glyph sequences
Generate a image after noticing 20 repeats
Time to Complete: 278 mili sec
Seq Len: Number of writes
1: 52248
2: 1172340
Total writes: 1224588
Total chars: 2396928
Total chars in file: 2396928
Improvement: 1.957334221795412
Images generated: 1358 (number of cached images of glyph sequence)
Nodes in Trie: 2396
—–
Up to 3 glyph sequences
Generate a image after noticing 20 repeats
Time to Complete: 564 mili sec
Seq Len: Number of writes
1: 47314
2: 132583
3: 694816
Total writes: 874713
Total chars: 2396928
Total chars in file: 2396928
Improvement: 2.740245086102527
Images generated: 5005 (number of cached images of glyph sequence)
Nodes in Trie: 15486
—
Upto 4 glyph sequences
Generate a image after noticing 20 repeats
Time to Complete: 1124 ms
Seq Len: Number of writes
1: 44938
2: 126648
3: 207050
4: 369386
Total writes: 748022
Total chars: 2396928
Total chars in file: 2396928
Improvement: 3.2043549521270767
Images generated: 10099 (number of cached images of glyph sequence)
Nodes in Trie: 39572